








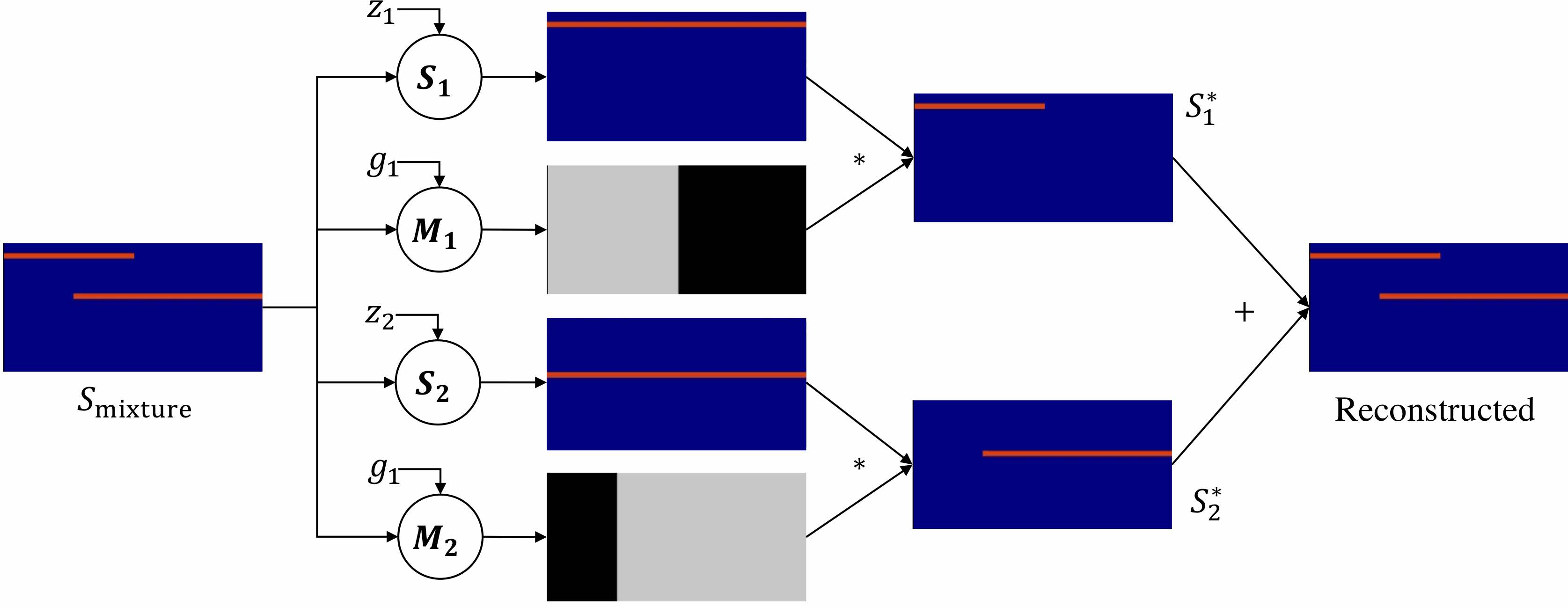
We introduce Deep Audio Prior (DAP) to address sound source separation problem without relying on any external training data.
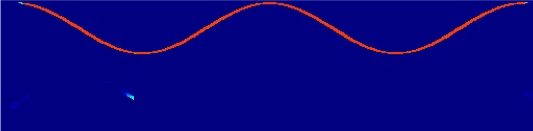
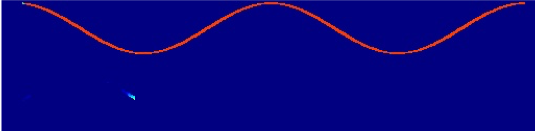
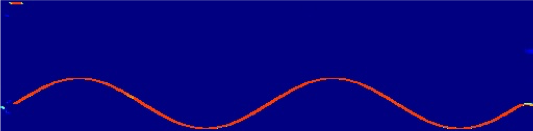
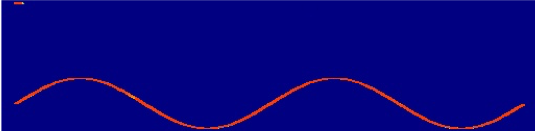
Two single-tone sources (top two rows) and two cosine-tone sources (bottom two rows). DAP achieves perfect separation on both input mixtures
| Input Mixed Audio | Predicted $S_1$ and $S_2$ | Predicted $M_1$ and $M_2$ | Final $S_1^*$ and $S_2^*$ |
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
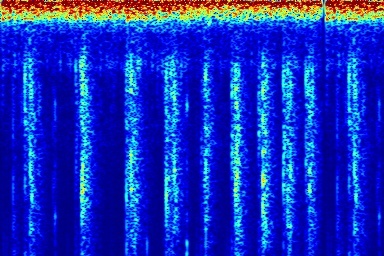
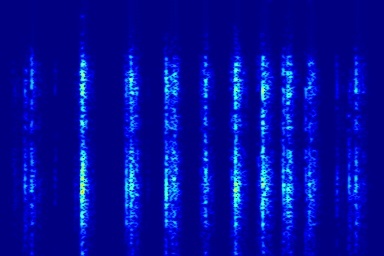
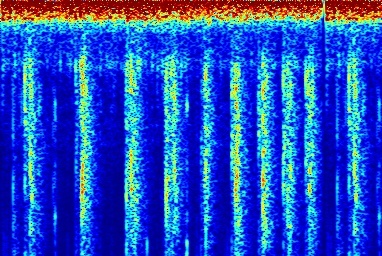
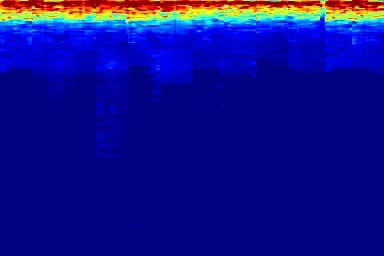
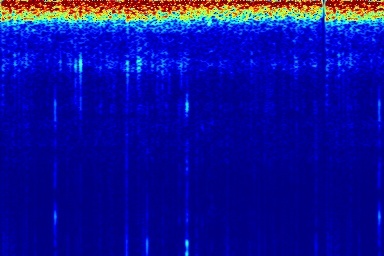
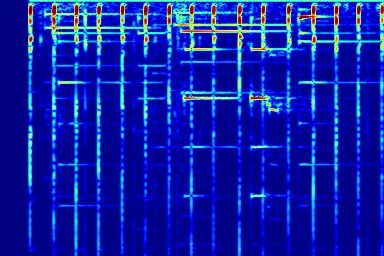
Audio comparison on Universal-150 benchmark. Qualitatively, DAP significantly outperforms all the other blind separation methods, including non-negative matrix factorization (NMF), robust principal component analysis (RPCA), and kernel additive modelling.
| Input Mixed Audio | NMF | RPCA | KAM | Proposed method: DAP | Ground Truth |
|---|---|---|---|---|---|
|
|

|
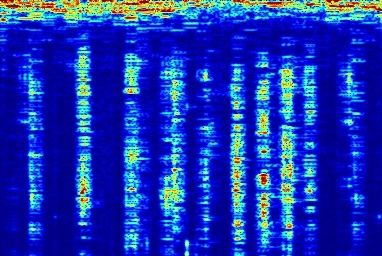
|
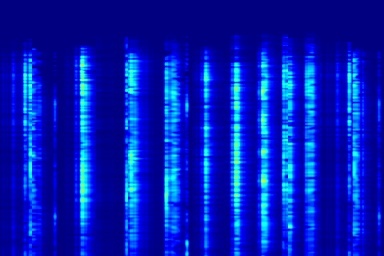
|

|
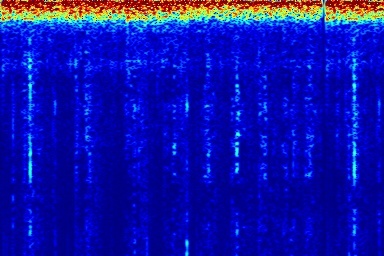
|
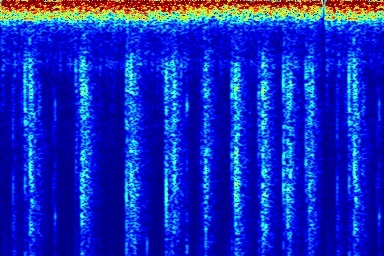
|
|
|
|
|
|
|
|
|

|
|
|

|
|
|
|
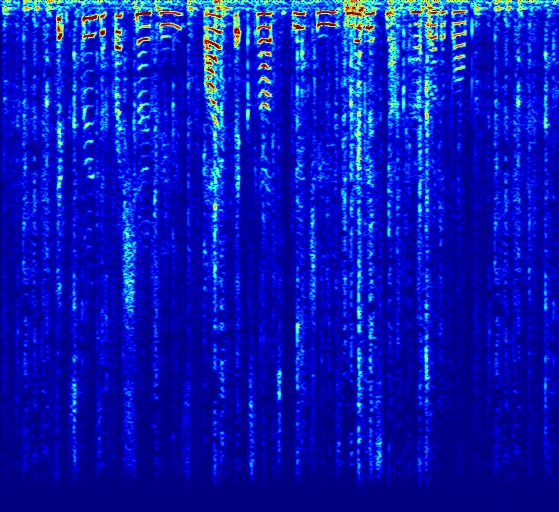
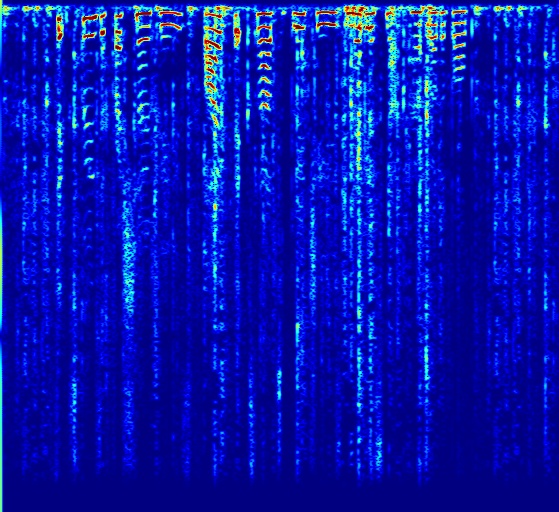
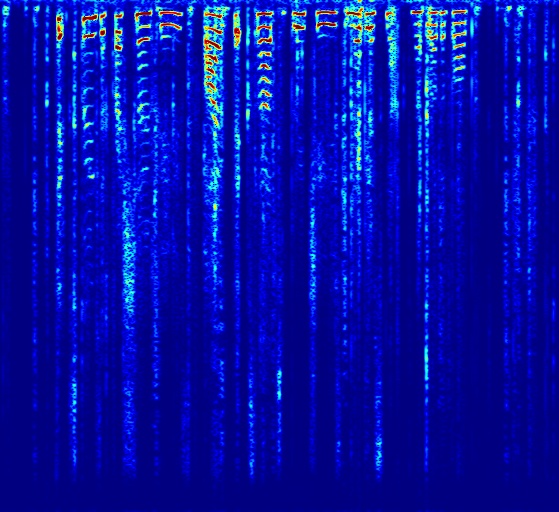
Comparison with other deep network models. DNP does not require training dataset and DAP achieve higher denoising quality. As for supervised models, for example SEGAN, that are trained on large dataset, although they usually work well on seen noises, it is hard to generalize to unseen noise. Here the speech is mixed with a noise that was not in the training set. While SEGAN did not remove the novel noise, DAP can better remove noises at the price of lower speech quality in some segments. Please listen to the sounds to appreciate the difference.
| Input Noisy Speech | DNP | SEGAN | DAP |
|---|---|---|---|
 |
 |
 |
 |
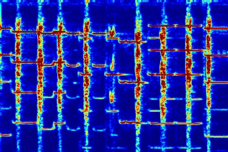
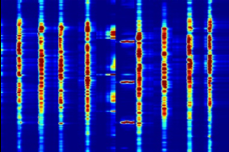
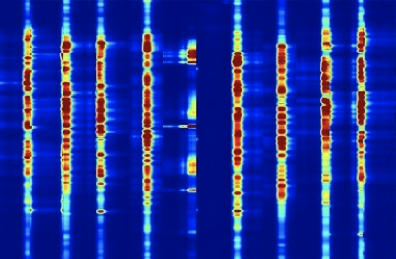
Given a sound mixture, our DAP model can predict separated sounds and the corresponding mask activation maps. Users can simply draw boxes to interact with our DAP model to tell where to deactivate or activate the predicted masks for refining predicted sounds. As shown, a user deactivate a region in the predicted mask for a separated sound, and then we obtain better results with the refined mask.
| Input Mixture | Initial Output $S_1$ / $M_1$ | Intuitive User Input | Refined Output $S_1$ / $M_1$ |
|---|---|---|---|
 |
 |
 |
 |

|

|
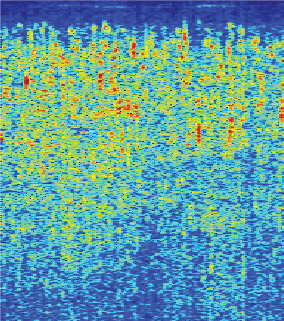
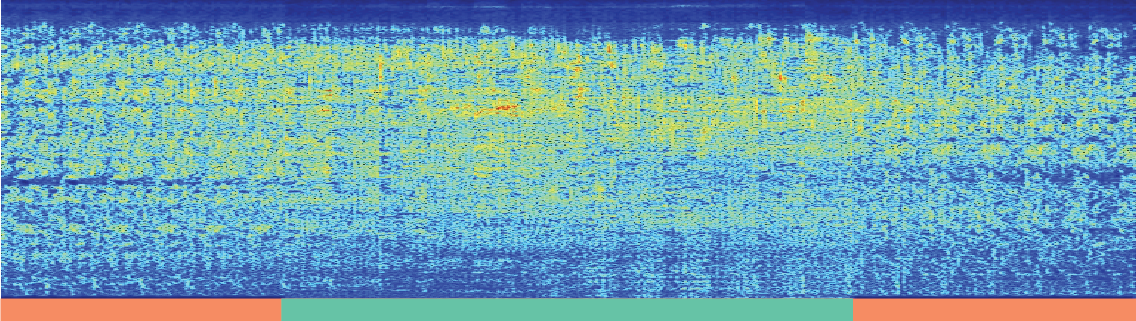
Audio texture synthesis via latent space editing. From a 3-second input audio, we can interpolate (in green) and extrapolate (in orange) the latent input noise to synthesize a seamless 12-second audio.
| Input 3-second Audio Texture | Output 12-second Synthesized Results |
|---|---|
 |
 |
DAP can also be applied to automatically remove audio watermark. Top row shows three audios A, B, and C, all mixed with watermark. Given these 3 mixtures, DAP can seperate each individual sound source out. Note that DAP is only trained on these 3 input audios.
| A + Watermark | B + Watermark | C + Watermark | |
|---|---|---|---|
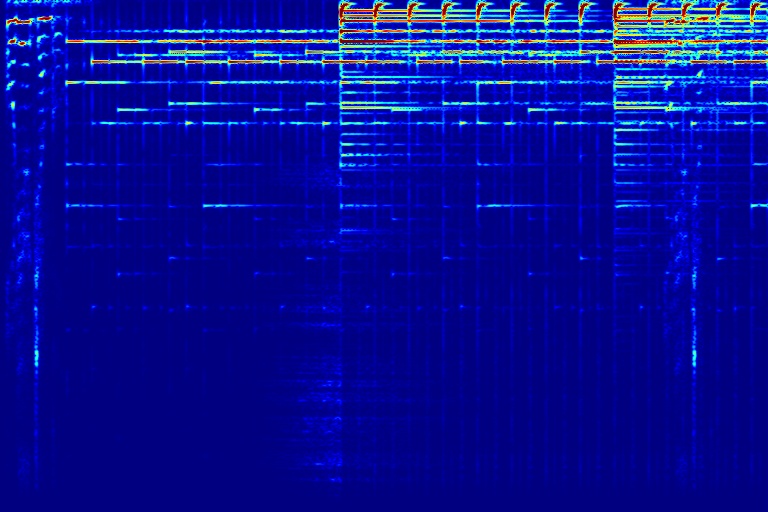 |
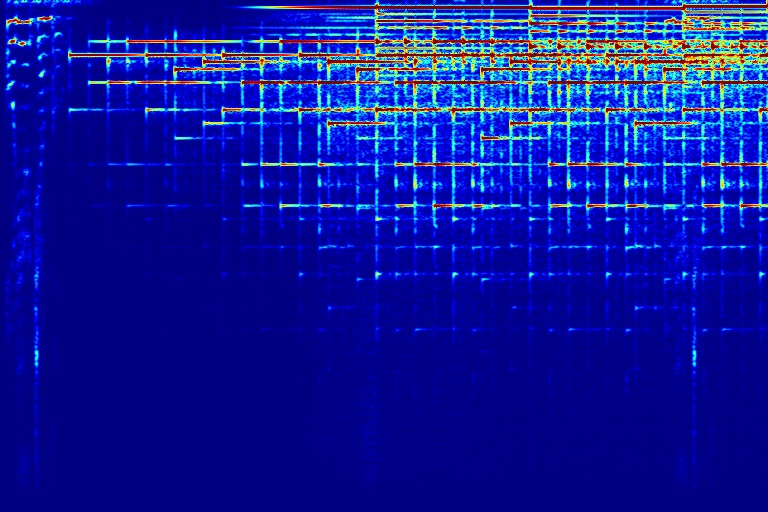 |
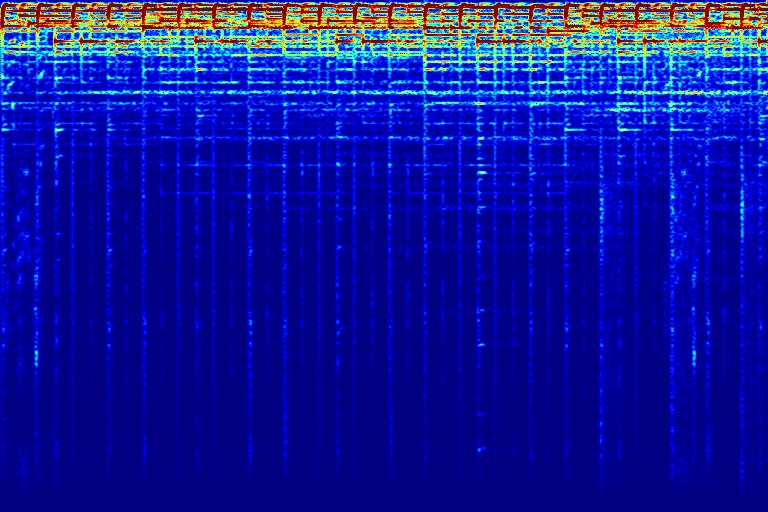 |
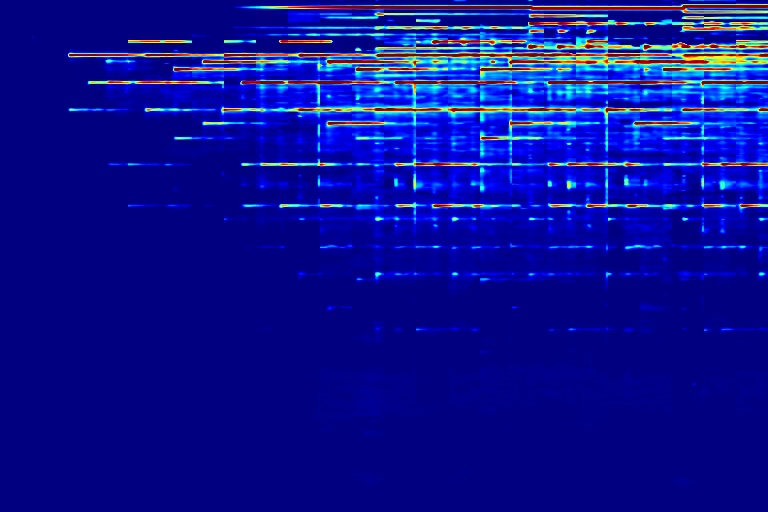
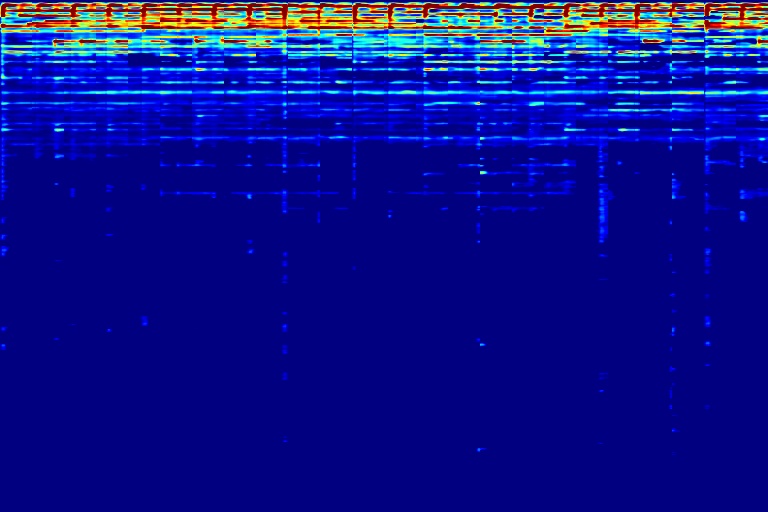
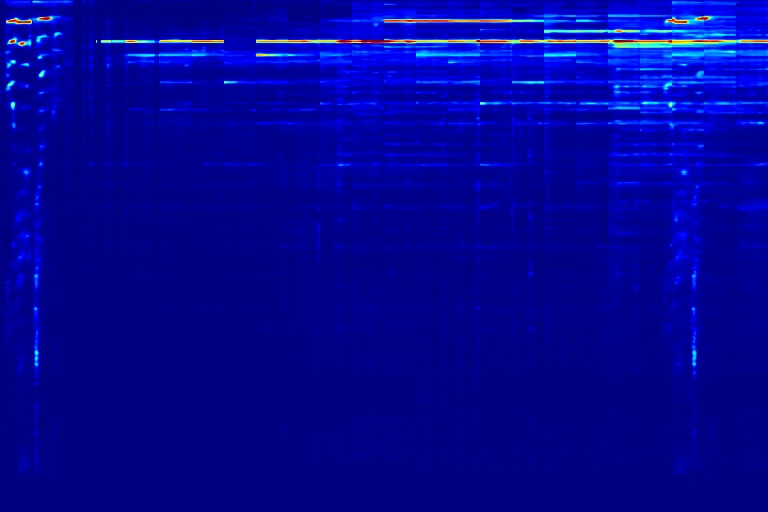
| A | B | C | Watermark |
|---|---|---|---|
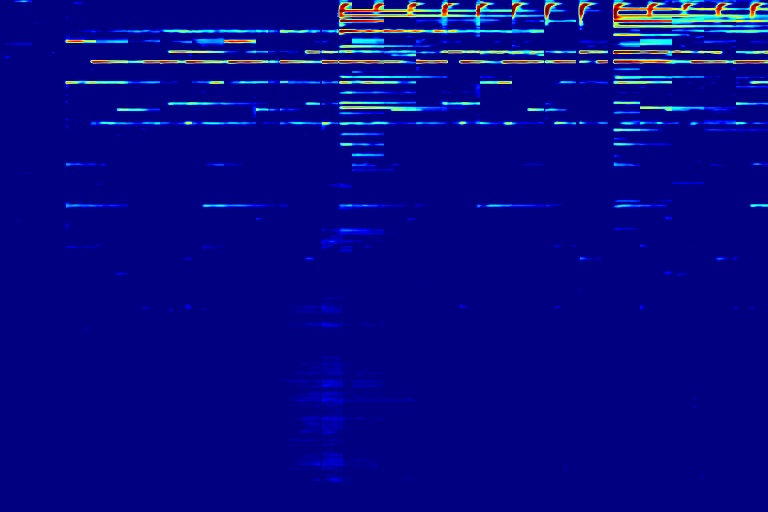 |
 |
 |
 |
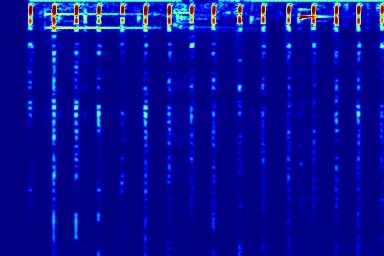
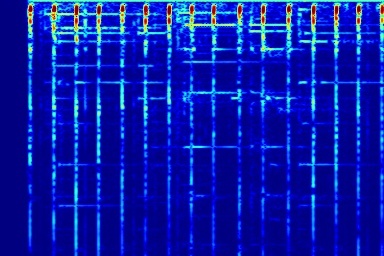
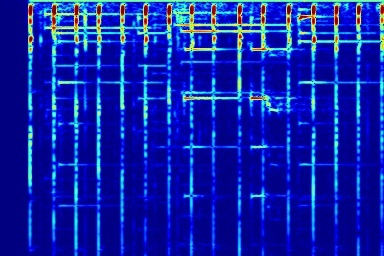
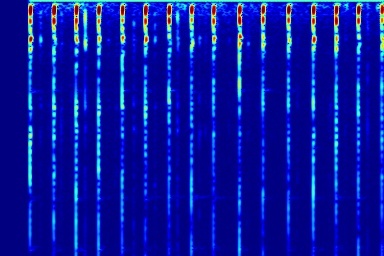
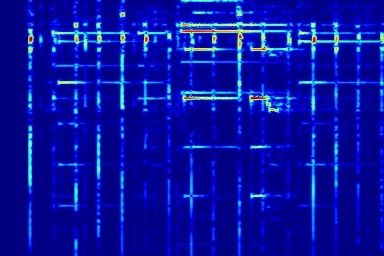
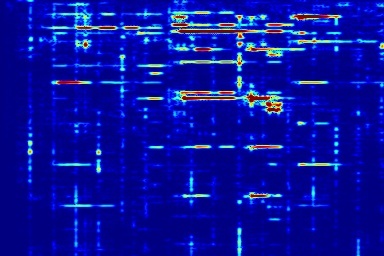
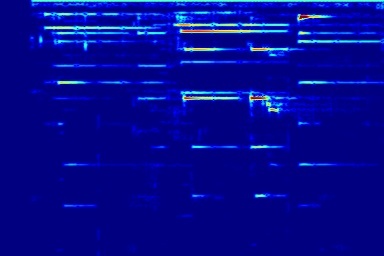
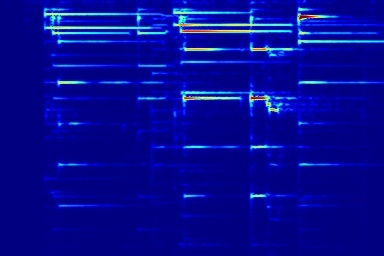
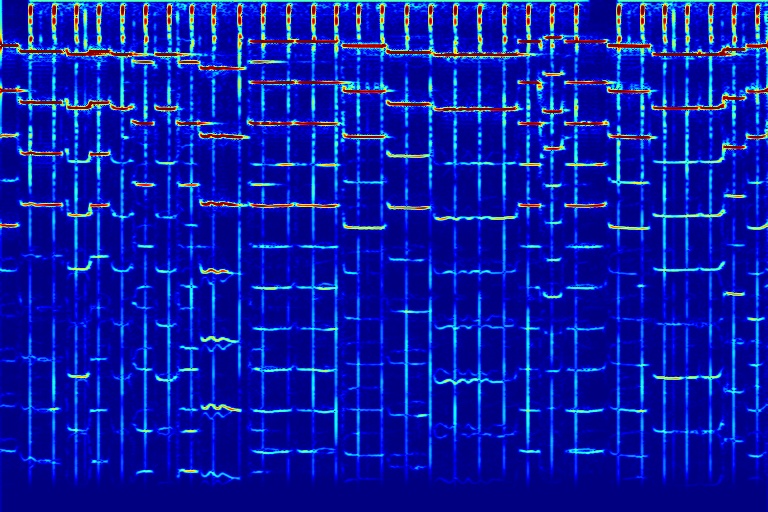
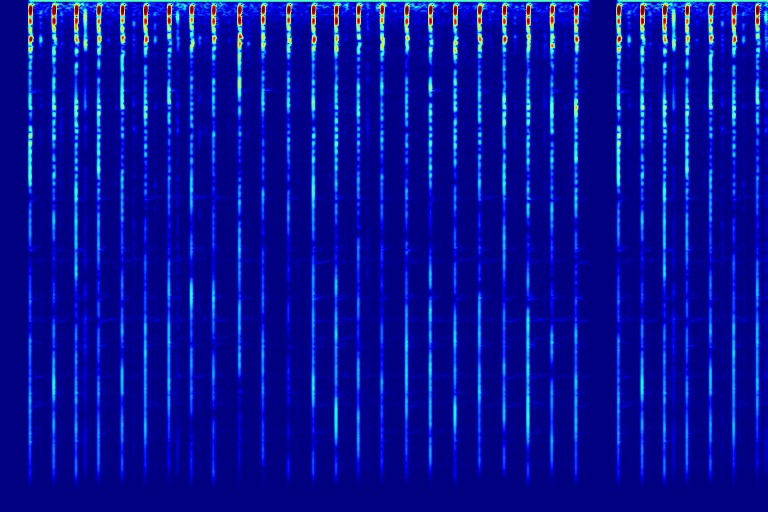
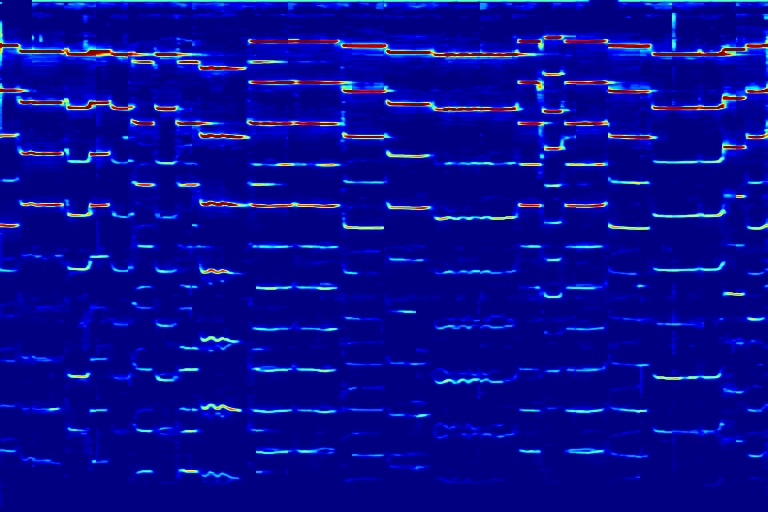
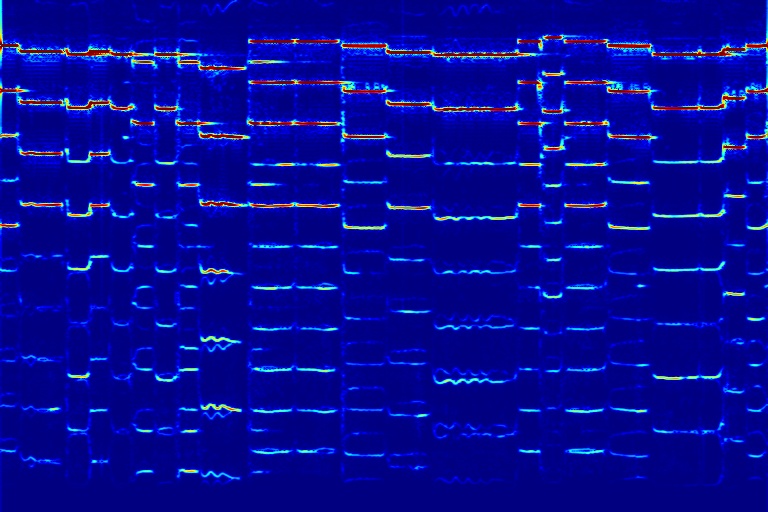
From left to right, spectrograms are from (a) input mixture (b) without temporal noise (w/o TN) (c) without dynamic noise (w/o DN) (d) without abrupt change in dynamic noise (w/o AC) (e) our full DAP model (f) ground truth.
| (a) Input | (b) w/o TN | (c) w/o DN | (d) w/o AC | (e) DAP | (f) Ground Turth |
|---|---|---|---|---|---|
|

|

|

|

|
|

|

|

|
|
|
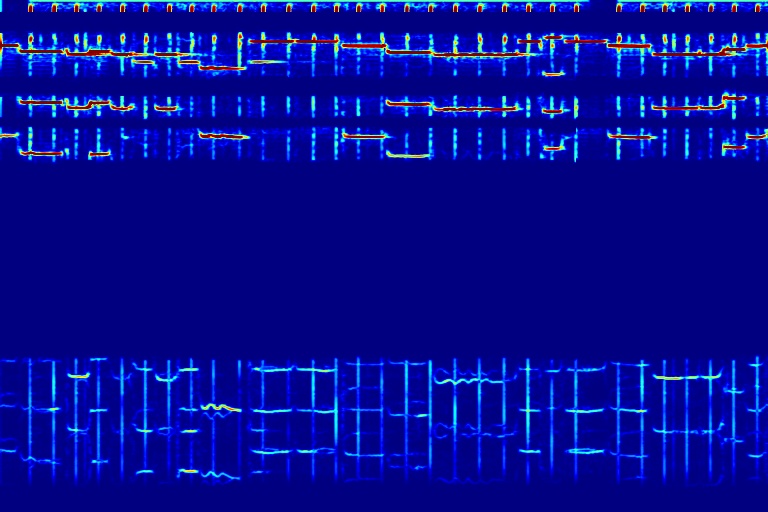
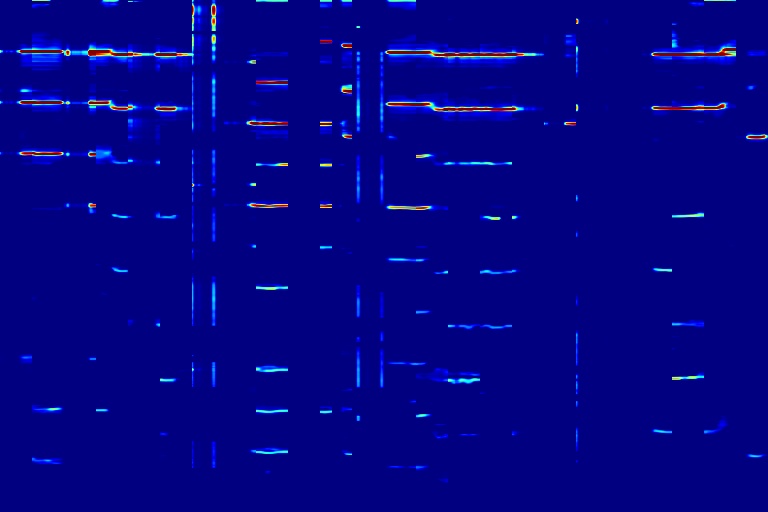
From left to right, spectrograms and masks are from models without 1D mask (w/o 1D), without nonzero mask loss (w/o NZ), and with both 1D mask and the loss (DAP).
| (a) w/o 1D | masks | (b) w/o NZ | masks | (c) DAP | masks |
|---|---|---|---|---|---|
 |
 |
 |
 |
|
 |
 |
 |
 |
 |
|
 |